데이터캠퍼스 교재 내용 토대로 타이핑하면서 실습한 내용 정리했습니다.
분류문제에서 2건의 에러 확인했습니다.

1) 분석 데이터 검토
유방암 데이터를 불러와서 세 가지 방법으로 확인한다.
head()
.value_counts(
print(data.shape)
import pandas as pd
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
#전부 영어라 encoding은 안해도 무방
#head()로 데이터셋 상위 수치 확인
data.head()
#레이블 변수(유방암) 비율 확인을 위해 빈도 확인
data['Class'].value_counts(sort=False)
#행과 열 구조 확인을 위해 shape 해보기
print(data.shape)
2) 특성(x)과 레이블 (y) 나누기
특성과 레이블을 나누는 방법으로 세 가지 방법이 있는데 이 중 내가 쓰기 편한 방법 골라쓰면 된다.
불러올 특성이 연달아 붙어 있다면 그냥 columns 단위(방법2)로 불러오는게 제일 편한듯!
(연달아 안붙어 있으면 일일히 변수 집어넣어서 가져오기..!)
- 특성 데이터 나눈 코드
#방법1: 특성이름으로 특성 데이터셋(X) 나누기
X1 = data[['Clump_Thickness', 'Cell_Size', 'Cell_Shape', 'Marginal_Adhesion', 'Single_Epithelial_Cell_Size', 'Bare_Nuclei',
'Bland_Chromatin', 'Normal_Nucleoli', 'Mitoses']]
#방법2: 특성 위치값으로 특성 데이터셋(X) 나누기
X2 = data[data.columns[1:10]]
#방법3: loc 함수로 특성 데이터셋(X) 나누기 (단, 불러올 특성이 연달아 있어야함)
X3 = data.loc[:, 'Clump_Thickness':'Mitoses']
print(X1.shape)
print(X2.shape)
print(X3.shape)- 레이블 데이터 나눈 코드
#레이블 데이터셋 나누기
y=data[["Class"]] #'[[]]' 대괄호 두 번 들어가게 감싸야 데이터프레임 형태가 됨. (1번은 시리즈형)
print(y.shape)이 때 대괄호를 한 번 감싸면 시리즈형 자료형이 되므로, 레이블 변수 명을 대괄호로 꼭 두 번 감싸주어야 한다.
3) train-test 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X1, y, stratify=y, random_state=42)
#stratify=y : 훈련데이터와 테스트데이터를 구분할 때, 레이블의 범주 비율에 맞게 하라는 것
#일반적으로 분류 알고리즘에서는 이 옵션을 적용하는 것을 추천한다.
#stratify=y 옵션을 걸어놔서 나눠진 데이터의 환자 비율이 비슷하게 나옴.
print(y_train.mean())
print(y_test.mean())학습용 데이터(train)와 테스트용 데이터(test) 구분을 위한 라이브러리는 사이킷런의 모델선택을 사용한다.
중간에 mean() 함수로 나눠진 데이터 평균 보는건 굳이 안해도 됨.
4) 정규화
#정규화 : 민맥스 또는 표준화를 사용
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
scaler_minmax=MinMaxScaler()
scaler_standard=StandardScaler()
#민맥스(MinMax) 방법으로 정규화
scaler_minmax.fit(X_train)
X_scaled_minmax_train=scaler_minmax.transform(X_train)
#표준화(Standard) 방법으로 정규화
scaler_standard.fit(X_train)
X_scaled_standard_train=scaler_standard.transform(X_train)
pd.DataFrame(X_scaled_minmax_train).describe()
pd.DataFrame(X_scaled_standard_train).describe()
#test data 정규화 : 민맥스(MinMax) 방법
X_scaled_minmax_test = scaler_minmax.transform(X_test)
pd.DataFrame(X_scaled_minmax_test).describe()
#test 데이터를 정규화할 때 fit 과정은 필요 없다. 훈련데이터에서 정규화 변환 기준을 이미 설정했기 때문이다.
#test data 정규화 : 표준화(Standard) 방법
X_scaled_standard_test = scaler_standard.transform(X_test)
pd.DataFrame(X_scaled_standard_test).describe()정규화의 방법에는 민맥스(MinMax), 표준화(Standard) 두 가지 중 한 가지를 골라 사용할 수 있다.
민맥스(MinMax)로 정규화를 하면 최솟값 0 ~ 최댓값 1 사이로 데이터를 변환시키고,
표준화(Standard)로 정규화를 하면 평균 0, 표준편차 1에 맞춰지도록 데이터를 변환시킨다.
위 코드는 민맥스, 표준화 두 가지를 모두 사용하여 데이터가 어떻게 변환되는지까지 확인하는 코드이다.
5) 모델학습
#모델 학습
from sklearn.linear_model import LogisticRegression
import numpy as np
model=LogisticRegression()
model.fit(X_scaled_minmax_train, np.ravel(y_train)) #오류 해결
#예측치
pred_train = model.predict(X_scaled_minmax_train) #predict은 결과가 정상(0), 환자(1)와 같은 범주값이 나온다.
model.score(X_scaled_minmax_train, y_train)내 불행은 모델학습 파트에서부터 시작되었음.
이 코드를 작성하고 나서 경고창 하나 뜨지만, 어차피 실행이 되었기에 대수롭지 않게 넘어가버렸다.

| DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True) |
다시 이 문제 해결하려고 경고 내용 부분 구글링, 코드 수정했는데 전체적으로 다 오류 생김 ㅎㅎ,,
원래 코드로 돌려놔도 말도 안되는 에러 계속 뜨길래 코드 첨부터 다시 쳤다,,
A column_vector y was passed when a 1d array was expected 이 오류 해결 방법은
#-------기존 코드--------#
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_scaled_minmax_train, y_train)
#------수정한 코드------#
import numpy as np
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_scaled_minmax_train, np.ravel(y_train))import numpy as np 추가해주고,
fit 함수 안의 y_train 변수를 np.ravel로 감싸주면 해결 할 수 있다.
뭐때문에 오류인지, 뭐때문에 해결된지 모르겠지만 이거때문에 거의 40분 시간 날림😂
6) 예측값 병합 및 저장
prob_train = model.predict_proba(X_scaled_minmax_train)
y_train[['y_pred']] = pred_train
y_train[['y_prob0', 'y_prob1']] = prob_train
y_train
prob_test = model.predict_proba(X_scaled_minmax_test)
y_test[['y_pred']] = pd.DataFrame(pred_test)
y_test[['y_prob0', 'y_prob1']] = prob_test
y_test교재에 나와있는 코드를 그대로 작성하여 실행시키니까 또 에러 발생했다.
pred_train이 리스트형태인데 데이터프레임에 넣으려고 하여 생기는 에러라고 한다
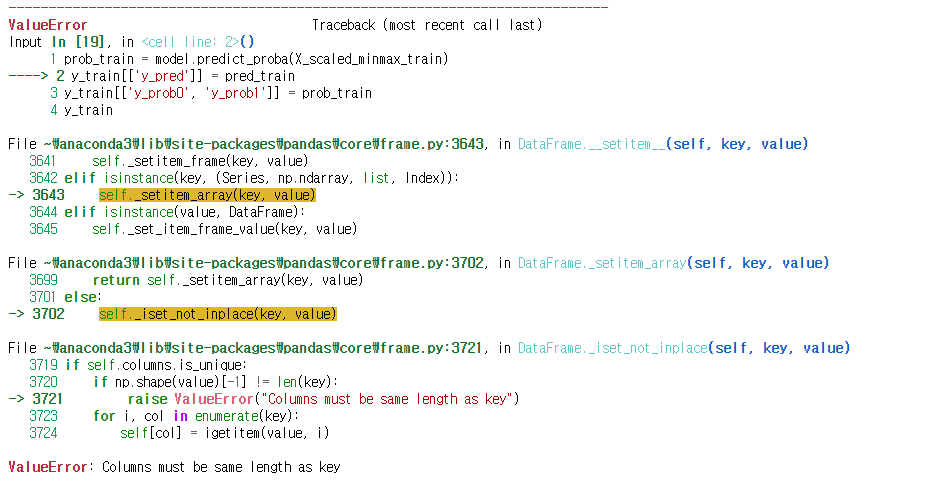
#-----에러나는 코드------#
prob_train = model.predict_proba(X_scaled_minmax_train)
y_train[['y_pred']] = pred_train
y_train[['y_prob0', 'y_prob1']] = prob_train
y_train
#-----에러 수정한 코드------#
prob_train = model.predict_proba(X_scaled_minmax_train)
y_train[['y_pred']] = pd.DataFrame(pred_train)
y_train[['y_prob0', 'y_prob1']] = prob_train
y_train데이터캠퍼스 홈페이지 들어가서 에러 수정한 코드 확인할 수 있었다.
즉문즉답 게시판에 3월에 올라온 질문을 무려 2개월만에 답장해주는 데이터캠퍼스..
나 교재 잘못고른듯 싶다.
Total_test = pd.concat([X_test, y_test], axis = 1)
Total_test
Total_test.to_csv("classfication_test.csv")'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 07 범주변수의 변환(원핫인코딩) (0) | 2022.06.17 |
|---|---|
| [빅데이터분석기사] 06 회귀문제 (0) | 2022.06.16 |
| [빅데이터분석기사] 04 데이터정제 실전과제 (0) | 2022.06.15 |
| [빅데이터분석기사] 03 결측치 처리(제거, 대체) (0) | 2022.06.14 |
| [빅데이터분석기사] 02 이상치 처리(log변환, 제곱근변환) (0) | 2022.06.13 |