
LogisticRegression의 핵심 하이퍼파라미터는 'C'이며, 디폴트는 'C=1'이다.
하이퍼파라미터를 찾는 두 가지 방법(그리드탐색, 랜덤탐색)을 실습해 볼 것이다.
그리드탐색과 랜덤탐색은 실제로 머신러닝에서 많이 사용된다.
그리트탐색은 분석자가 모델, 하이퍼파라미터에 대한 경험과 직관이 있어야 좋은 결과를 보이며,
랜덤탐색은 무작위로 많이 찾아 돌려보는 탐욕적(greedy) 방법이고, 일반적으로 매우 효과적이다.
(물리적 연산장치가 뒷받침되어야 한다는 조건도 있음)
1) 데이터 불러오기
#분석결과 외에 불필요한 내용이 나오지 않도록 하는 옵션
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data=pd.read_csv('Fvote.csv', encoding='utf-8')import warnings
warnings.filterwarnings("ignore")
분석결과 외에 불필요한 내용이 나오지 않도록 하는 옵션이다.
X=data[data.columns[1:13]]
y=data[['vote']]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)특성치(X)와 레이블(y) 데이터셋을 구분해주었고,
훈련 데이터와 테스트 데이터를 7:3 비율로 분할하는 과정
2) Grid Search
#그리드탐색
#분석자가 하이퍼파라미터의 특정값을 지정하고, 각각 모델에 적용하여 모델적합도를 비교하는 방법
from sklearn.model_selection import GridSearchCV
param_grid = {'C' : [0.001, 0.01, 0.1, 1, 10, 100]}그리드탐색을 위해 sklearn.model_selection에서 GridSeartCV를 가져온다.
하이퍼파라미터 'C' 값을 6개로 지정했다.
from sklearn.linear_model import LogisticRegression
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5, return_train_score=True)
grid_search.fit(X_train, y_train)
하이퍼파라미터 설정이 끝났으면 LogisticRegression 알고리즘을 불러온다.
그리드서치의 형식은 다음과 같다. (return_train_score의 디폴트값은 False이다.)
GridSearchCV(알고리즘모델, 설정한 그리드서치, cv(옵션), return_train_score(옵션))
print("Best Parameter: {}".format(grid_search.best_params_))
print("Best Cross-validity Score: {:.3f}".format(grid_search.best_score_))
print("Test set Score: {:.3f}".format(grid_search.score(X_test, y_test)))정확도가 가장 높은 하이퍼파라미터(C) 확인 : grid_search.best_params_
정확도 확인 : grid_search.best_score_
result_grid = pd.DataFrame(grid_search.cv_results_)
result_grid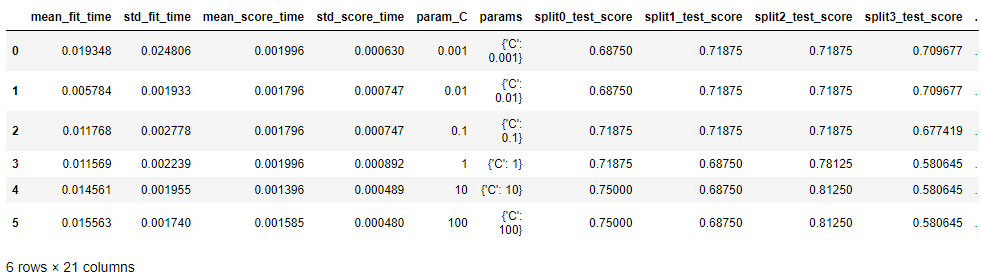
그리드서치 하이퍼파라미터별, cross validation별 상세 결과값을 확인하고 싶다면
grid_search.cv_results_를 데이터프레임 형태로 출력하면 된다.
3) Random Search
랜덤탐색은 sklearn.model_selection으로부터 RandomizedSearchCV 라이브러리를 불러온다.
범위를 내가 지정하면 그 안에서 무작위로 C값을 찾아낸다.
#Random Search
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs={'C': randint(low=0.001, high=100)}
from sklearn.linear_model import LogisticRegression랜덤하게 뽑아햐하니 randint 라이브러리를 추가로 사용해주었다.
param_distribs 변수를 만들어서 최소 0.001(low), 최대 100(high)로 범위를 지정했다.
random_search=RandomizedSearchCV(LogisticRegression(), param_distributions=param_distribs,
cv=5, return_train_score=True)
random_search.fit(X_train, y_train)RandomizedSearchCV의 n_iter 옵션은 랜덤하게 C값을 몇 번 뽑는가를 정한다. (랜덤횟수는 디폴트 10)
여기서 추가하지 않았지만 n_iter=100으로 설정하면 100개의 모델 결과가 제시된다.
여기선 교차검증(cv)만 5로 설정하고, 훈련데이터 정확도 결과 제시(True) 정도 추가했다.
print("Best Parameter: {}".format(random_search.best_params_))
print("Best Cross-validity Score: {:.3f}".format(random_search.best_score_))
print("Test set Score: {:.3f}".format(random_search.score(X_test, y_test)))

정확도가 가장 높은 하이퍼파라미터는 C=66으로 나타났다.
하이퍼파라미터별, cv별 상세 결과값을 확인하고 싶다면
random_search.cv_result_를 데이터프레임 형식으로 출력해보자.
'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 12 다중분류 (0) | 2022.06.20 |
|---|---|
| [빅데이터분석기사] 11 모델평가 (0) | 2022.06.20 |
| [빅데이터분석기사] 09 데이터 정규화 (0) | 2022.06.19 |
| [빅데이터분석기사] 08 데이터셋 분할과 모델검증 (0) | 2022.06.18 |
| [빅데이터분석기사] 07 범주변수의 변환(원핫인코딩) (0) | 2022.06.17 |