
앙상블 배깅
학습 데이터에 대해 여러 개의 부트스트랩 데이터를 생성하고 각 부트스트랩 데이터에 하나 혹은 여러 알고리즘을 학습시킨 후 산출된 결과 중 투표 방식에 의해 최종 결과를 선정하는 알고리즘이다.
scikit-learn
배깅 방법은 사이킷런의 ensemble 안에 있다.
이 중 분류는 BaggingClassifier이고,
회귀는 BaggingRegressor이다.
BaggingClassifier과 BaggingRegressor의 기본 옵션은 동일하다.
base_estimator에 알고리즘을 설정하고 n_estimator가 부트스트랩을 통해 몇 개의 데이터셋을 구성할지 결정한다.
Part1. 분류(Classification) : BaggingClassifier
1. 데이터셋 분리와 정규화
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
X=data[data.columns[1:10]]
y=data[["Class"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
#min-max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)유방암 데이터셋으로 실습 진행한다.
2. 모델 적용
from sklearn.svm import SVC
from sklearn.ensemble import BaggingClassifier
model = BaggingClassifier(base_estimator=SVC(), n_estimators=10, random_state = 0)
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)BaggingClassifier의 기본 알고리즘으로 서포트벡터머신을 설정했다.
SVC와 BaggingClassifier를 각각 import한 뒤, model엔 배깅, base_estimator는 SVC, n_estimators는 10으로 한다.
10개의 데이터셋에 SVC를 훈련시켜 결과를 종합한다는 의미이다.
3. 혼동행렬과 분류예측 레포트
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 혼동행렬:\n", confusion_train)
from sklearn.metrics import classification_report
cfreport_train = classification_report(y_train,pred_train)
print("분류예측 레포트:\n", cfreport_train)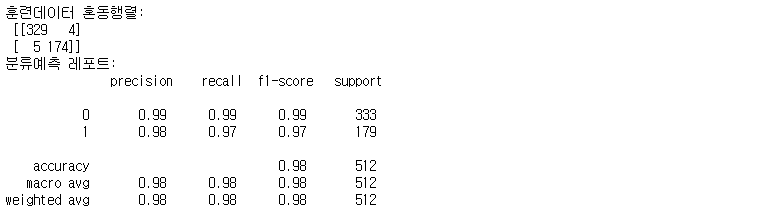
훈련데이터의 모델 성능은 0.98수준,
테스트데이터의 모델 성능은 0.95~0.96 수준으로 나타나고 있따.
Part2. 회귀(Regression) : BaggingRegressor
1. 데이터셋 분리와 정규화
import pandas as pd
data2 = pd.read_csv('house_price.csv', encoding='utf=8')
X=data2[data2.columns[1:5]]
y=data2[["house_value"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)주택가격 데이터로 배깅의 회귀 알고리즘을 실습해본다.
2. 모델 적용
#Part2. 회귀(Regression) : BaggingRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import BaggingRegressor
model = BaggingRegressor(base_estimator=KNeighborsRegressor(), n_estimators=10, random_state=0)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)여기서는 KNeighborsRegressor을 기저 모델로 정했다.
base_estimator = KNeighborsRegressor(), n_estimators=10으로 설정했다.
정확도는 69.3%로 꽤 높은 수준을 나타내었다.
코드 실습할때 여기서 또 원인 모를 에러가 났는데,
새 파일 생성하고 Part2부분 코드 옮기니까 적상작동 했다.
3) RMSE 오차 계산
#RMSE(Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련데이터 RMSE: ", np.sqrt(MSE_train))
print("테스트데이터 RMSE: ", np.sqrt(MSE_test))
오차의 경우 훈련데이터는 52.9%, 테스트데이터는 63%로 나왔다.
이걸 퍼센트화 시킬 수 있는건 처음 알았다... 그저 만단위의 큰 수가 아니었구나..
'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 23 앙상블 스태킹 (0) | 2022.06.24 |
|---|---|
| [빅데이터분석기사] 22 앙상블 부스팅 (0) | 2022.06.23 |
| [빅데이터분석기사] 20 투표기반 앙상블 (0) | 2022.06.23 |
| [빅데이터분석기사] 19 랜덤포레스트 (0) | 2022.06.22 |
| [빅데이터분석기사] 18 의사결정나무 (0) | 2022.06.22 |