
의사결정나무
의사결정 규칙을 나무구조로 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류하거나 특정 값을 예측하는데 활용되는 방법이다.
결과를 직관적으로 도식화하여 볼 수 있고, 어떻게 분류되는지 알 수 있다는 장점이 있다.
하지만 분류되는 단계가 많아지면 이해하기 어려워지고, 데이터에 따라 결과가 안정적이지 못하다는 단점이 있다.
주로 특성치가 많지 않고 최종 알고리즘을 도출하기 전 탐색적으로 주요한 분류 변수가 어떤 것인지 확인하는데 사용된다.
scikit-learn
의사결정나무는 사이킷런의 tree 안에 있다.
이 중 DecisionTreeClassifier가 분류 알고리즘,
DecisionTreeRegressor를 회귀 알고리즘으로 사용한다.
의사결정나무분석에서 분류의 경우 기준은 'gini'이고 회귀의 기준은 'mse'이다.
다양한 하이퍼파라미터 중 분류나 회귀 결과에 영향을 미치는 것은 'max_depth, max_leaf_node, min_sample_leaf'이다.
max_depth : 얼마나 많은 단계로 분류할 것인가
max_leaf_node :얼마나 많은 노드를 만들 것인가
min_sample_leaf : 한 노드에서 최소 표본수는 몇 개일 때 별개 집단으로 분류하게 할 것인가
현실적으로 min_sample_leaf외에 다른 하이퍼파라미터는 결정하기 다소 어려움이 있다.
Part1. 분류(Classification) : DecisionTreeClassifier
의사결정나무는 학습데이터에 과적합되는 경향을 보인다. 하이퍼파라미터의 설정에 대한 기준도 논리적으로 설정하기 어렵다. 이런 단점이 있어도 기본적 방향을 탐색하기 위한 초기 분석모델로서는 유용하며, 실제 분석에서는 의사결정나무의 앙상블인 랜덤포레스트를더 선호한다.
1) 데이터셋 분리와 정규화
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
X=data[data.columns[1:10]]
y=data[["Class"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
#min-max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)유방암 데이터로 실습을 진행했다.
이제 교재엔 어떤 데이터로 실습을 진행할건지 알려주지 않는다.
분류는 유방암, 회귀는 집값 데이터 눈치껏 보고 사용중이다.
2) 기본모델 적용
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)sklearn.tree로부터 DecisionTreeClassifier 라이브러리를 가져왔다.
model = DecisionTreeClassifier()로 설정하여 분석했더니 정확도가 무려 100%가 나온다.
3) 혼동행렬과 분석예측 레포트
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)
from sklearn.metrics import classification_report
cfreport_train = classification_report(y_train, pred_train)
print("분류예측 레포트:\n", cfreport_train)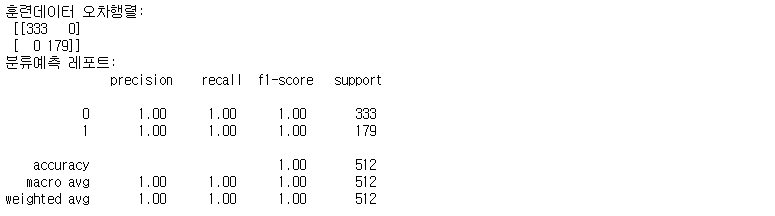
훈련데이터의 모델 성능에 대한 예측 레포트를 보면 모두 100% 결과를 보이고 있다.
테스트데이터는 정확도가 100%까지 나오지 못했다. 훈련데이터에 과대적합 되었다고 판단할 수 있다.
4) Grid Search
#Grid Search
param_grid = {'max_depth': range(2,20,2), 'min_samples_leaf': range(1,50,2)}
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_scaled_train, y_train)
print("Best Parameter:{}".format(grid_search.best_params_))
print("Best Score:{:.4f}".format(grid_search.best_score_))
print("TestSet Score:{:.4f}".format(grid_search.score(X_scaled_train, y_train)))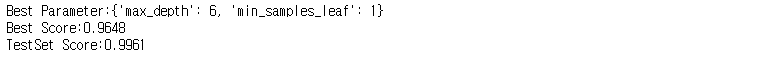
하이퍼파라미터 중 max_depth와 min_samples_leaf 수치 설정하여 탐색해보았다.
탐색 결과 max_depth = 6, min_samples_leaf = 1일 때 최적의 조합이라고 한다.
5) Random Search
#Random Search
from scipy.stats import randint
param_distribs = {'max_depth': randint(low=1,high=20),'min_samples_leaf':randint(low=1,high=50)}
from sklearn.model_selection import RandomizedSearchCV
random_search = RandomizedSearchCV(DecisionTreeClassifier(),param_distributions=param_distribs, n_iter=20, cv=5)
random_search.fit(X_scaled_train, y_train)
print("Best Parameter:{}".format(random_search.best_params_))
print("Best Score:{:.4f}".format(random_search.best_score_))
print("TestSet Score:{:.4f}".format(random_search.score(X_scaled_train, y_train)))
랜덤탐색에서는 max_depth 1~20, min_samples_leaf 1~50사이로, 무작위 20개의 모델(n_iter=20)로 분석했다.
탐색 결과 최적의 하이퍼파라미터는 max_depth = 19, min_sampes_leaf = 1로 확인되었다.
Part2 : 회귀(Regression) : DecisionTreeRegressor
회귀문제에서도 기본모델에서는 과대적합되는 경향을 보인다. 적절한 하이퍼파라미터를 찾으면 일반화 가능성도 높아진다. 데이터에 맞는 적절한 하이퍼파라미터를 찾는게 관건이 되겠다.
1) 데이터셋 분리와 정규화
import pandas as pd
data2 = pd.read_csv('house_price.csv', encoding='utf=8')
X=data2[data2.columns[1:5]]
y=data2[["house_value"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)주택가격.csv 기존에 썼던거 그대로 사용했다.
2) 기본모델 적용
#Part2. 회귀(Regression)
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train,y_train)
pred_test = model.predict(X_scaled_test)
model.score(X_scaled_test, y_test)sklearn.tree로부터 DecisionTreeRegressor 라이브러리를 불러왔다.
model = DecisionTreeRegressor()로 설정하여 fit, predict, score(정확도) 순으로 코드 실행했다.
코드 실행 결과 훈련데이터의 정확도는 100%, 테스트데이터의 정확도는 21%로 격차가 매우 컸다.
3) RMSE 오차 확인
#RMSE(Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련데이터 RMSE:", np.sqrt(MSE_train))
print("테스트데이터 RMSE:", np.sqrt(MSE_test))
훈련데이터 오차는 0, 테스트데이터는 84,112가 나왔다.
오차는 작을수록 좋은거니까 얼마나 과대적합 문제가 심한지 알 수 있다.
4) Grid Search
#Grid Search
param_grid = {'max_depth':range(2,20,2), 'min_samples_leaf':range(1,50,2)}
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(DecisionTreeRegressor(), param_grid, cv=5)
grid_search.fit(X_scaled_train,y_train)
print("Best Parameter:{}".format(grid_search.best_params_))
print("Best Score:{:.4f}".format(grid_search.best_score_))
print("TestSet Score:{:.4f}".format(grid_search.score(X_scaled_train, y_train)))
max_depth와 min_samples_leaf를 기준으로 설정하였다.
탐색 결과 최적의 하이퍼파라미터는 max_depth=8, min_samples_leaf=49일때 최적의 조합으로 나타났다.
훈련 데이터의 정확도, 테스트데이터 정확도는 둘 다 50% 대
5) Random Search
#Random Search
param_distribs = {'max_depth': randint(low=1, high=20), 'min_samples_leaf':randint(low=1,high=50)}
from sklearn.model_selection import RandomizedSearchCV
random_search = RandomizedSearchCV(DecisionTreeRegressor(),param_distributions=param_distribs, cv=5, n_iter=20)
random_search.fit(X_scaled_train,y_train)
print("Best Parameter:{}".format(random_search.best_params_))
print("Best Score:{:.4f}".format(random_search.best_score_))
print("TestSet Score:{:.4f}".format(random_search.score(X_scaled_train, y_train)))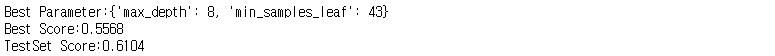
최적의 하이퍼파라미터는 max_depth = 8, min_samples_leaf = 43으로 나타났다.
훈련데이터 정확도 55%, 테스트데이터 정확도는 61%로 나타났다.
'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 20 투표기반 앙상블 (0) | 2022.06.23 |
|---|---|
| [빅데이터분석기사] 19 랜덤포레스트 (0) | 2022.06.22 |
| [빅데이터분석기사] 17 서포트 벡터머신 (0) | 2022.06.22 |
| [빅데이터분석기사] 16 인공신경망 (0) | 2022.06.21 |
| [빅데이터분석기사] 15 나이브 베이즈 (0) | 2022.06.21 |