
선형회귀모델(linear regression model)
연속형 원인변수가 연속형 결과변수에 영향을 미치는지를 분석하여 레이블 변수를 예측하기 위한 목적으로 활용된다.
선형회귀모델에서 RMSE가 가장 대표적인 오차 지표이다. 의미는 '실제값과 예측값 간에 전 구간에 걸친 평균적인 오차'로서 실제 레이블(y)의 단위를 그대로 반영하여 해석이 쉽다.
scikit-learn
선형회귀모델은 사이킷런의 linear_model에 있다. 이 중 LinearRegression이 선형회귀 알고리즘이다.
선형회귀모델은 특별한 하이퍼파라미터가 없다.
normalize는 특성치(X)의 정규화인데 보통 데이터를 정규화하여 모델에 투입하기 때문에 False로 둔다.
intercept는 X가 0일때 Y의 기본값인 상수를 모델에 반영할지 여부인다. 상수는 대부분 필요하기 때문에 그대로 둔다.
1) statmodel 적용
import statsmodels.api as sm
x_train_new = sm.add_constant(X_train)
x_test_new = sm.add_constant(X_test)
x_train_new.head()
머신러닝 모델을 적용하기 전 파이썬의 통계분석 모듈인 statmodel로 주택가격 데이터를 분석해보겠다.
주택가격 데이터를 train_test_split한 X_train을 상수항 변수를 더하여(sm.add_constant) x_train_new라는 변수로 만들고 X_test도 동일하게 X_test_new라고 한다. 'const'라는 변수가 모두 '1'로 되어 있는데 이 변수가 상수를 추정하는 역할을 한다.
multi_model = sm.OLS(y_train, x_train_new).fit()
print(multi_model.summary())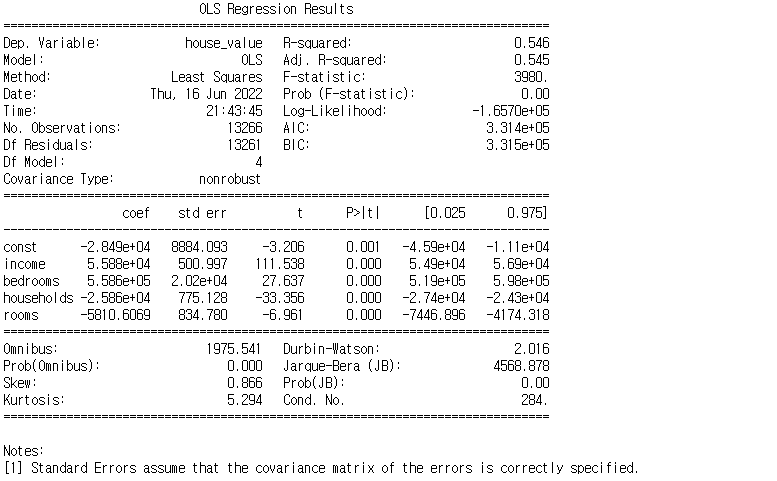
다음 sm.OLS를 적용하고 바로 훈련(fit())한다. (y데이터셋, x데이터셋 위치 주의)
결과 데이터에서 R-squared는 결정계수,
coef는 X변수가 1증가할 때 Y가 변화하는 정도, 즉 기울기를 뜻한다.
예를들어 income이 1증가할 때 house_value는 약 5.6만 달러 증가한다는 의미이다.
p<|t| 값은 0.05보다 작으면 통계적으로 유의하다는 의미를 갖는다.
이후 테스트 데이터의 summary() 데이터를 보니 모든 X변수가 유의하게 나타나는 것을 확인했다.
Scikit-learn적용
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)
pred_test = model.predict(X_scaled_test)
model.score(X_scaled_test, y_test)위 코드를 실행하여 설명력(score)을 확인해보니, 통계모델에서 봤었던 R-squared와 동일하게 54.6%가 나왔다.
테스트데이터셋도 예측치를 저장하여 정확도를 살펴보니 통계모델과 동일한 수치로 나온다.
RMSE 오차 확인
#RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print(np.sqrt(MSE_train))
print(np.sqrt(MSE_test))
RMSE를 확인해보았더니 훈련데이터, 테스트데이터 모두 6.3~6.4만정도 나왔다.
실제 집값과 예측된 집값 간 평균적인 오차가 약 6.3~6.4만 정도 된다는 뜻이다.
절대평균오차(MAE)
#기타 선형 모델평가지표: MAE(Mean Absolute Error)
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test, pred_test)
실제값과 예측값의 차이에 절대값을 씌어 평균을 낸 오차이다.
4.7만정도가 나왔다.
평균제곱오차(MSE)
#기타 선형 모델평가지표: MSE(Mean Squared Error)
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, pred_test)
평균제곱오차는 실제값과 예측값의 차이, 오차에 제곱을 한 오차 지표이다.
제곱을 했기 때문에 수치가 매우 크게 나온다. (여기에 루트를 씌우면 RMSE가 된다.)
평균절대오차비율(MAPE)
#기타 선형 모델평가지표: MAPE(Mean Absolute Percentage Error)
def MAPE(y_test, y_pred):
return np.mean(np.abs((y_test-pred_test)/y_test))*100
MAPE(y_test, pred_test)평균절대오차비율은 실제값 대비 오차(실제값-예측값_정도를 백분률로 나타낸 지표이다.
일반적인 선형회귀모델보다는 시계열 데이터에서 주로 이용한다.
직접 함수를 만들어 계산해주었다.
평균오차비율(MPE)
#기타 선형 모델평가지표: MPE(Mean Percentage Error)
def MPE(y_test, y_pred):
return np.mean((y_test-pred_test)/y_test)*100
MPE(y_test,pred_test)평균오차비율을 보면 0을 기준으로 실제값보다 예측값이 더 큰지, 작은지 등을 알 수 있다.
'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 26 라쏘회귀모델 (0) | 2022.06.25 |
|---|---|
| [빅데이터분석기사] 25 릿지회귀모델 (0) | 2022.06.24 |
| [빅데이터분석기사] 23 앙상블 스태킹 (0) | 2022.06.24 |
| [빅데이터분석기사] 22 앙상블 부스팅 (0) | 2022.06.23 |
| [빅데이터분석기사] 21 앙상블 배깅 (0) | 2022.06.23 |