
군집분석(Cluster Analysis)
개체들의 특성을 대표하는 몇 개의 변수들을 기준으로 몇 개의 그룹(군집)으로 세분화하는 방법이다. 개체들을 다양한 변수를 기준으로 다차원 공간에서 유사한 특성을 가진 개체로 묶는다.
개체들 간 유사성은 개체 간의 거리를 사용하고, 거리가 상대적으로 가까운 개체들을 동일 군집으로 묶는다. 개체 간의 거리는 대표적으로 유클라디안 거리로 계산한다.
scikit-learn
군집분석은 사이킷런에서 cluster 모듈에 있다. 이 중 KMeans가 대표적인 군집분석 알고리즘이다.
KMeans의 옵션 중 가장 핵심적인 것은 n_clusters, 몇 개의 군집을 묶을건지 결정한다.
1) 기본 라이브러리 불러오기
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-deep')
import matplotlib.cm
cmap = matplotlib.cm.get_cmap('plasma')
from sklearn.cluster import KMeansnumpy, pandas, matplotlib.pyplot, matplotlib.cm, Kmeans 등 굉장히 많은 라이브러리를 불러왔다.
data = pd.read_csv('Mall_Customers.csv')
X = data.iloc[:,[3,4]]
X.head()분석데이터로는 'Mall_Customers.csv' 파일을 불러와 인덱스 3,4번 변수(Income, Spend)만 사용했다.
wcss = []
for i in range(1,21):
kmeans = KMeans(n_clusters=i)
kmeans.fit_transform(X)
wcss.append(kmeans.inertia_)
wcss
plt.figure()
plt.plot(range(1,21), wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
통계기준으로 최적의 군집수를 찾기 위해 군집수를 1~21개까지 늘려보면서 'kmeans.inertia_' 값을 살펴봤다.
'kmeans.inertia_'는 군집의 중심과 각 케이스(개체) 간 거리를 계산한다.
일반적으로 거리가 작을수록 군집 형성 잘 되어있다고 보지만, 크게 감소하다 변화가 없는 지점에서 k를 결정한다.
위 그래프를 보면 k=5로 결정하는 것이 적당하다는 것을 알 수 있다.
k=5
kmeans = KMeans(n_clusters = k)
y_kmeans = kmeans.fit_predict(X)
y_kmeans
KMeans()안에 n_clusters=k를 넣어주고
학습과 예측(kmeans.fit_predict(X))을 하고 군집 결과를 y_kmeans에 담았다.
Group_cluster = pd.DataFrame(y_kmeans)
Group_cluster.columns=['Group']
full_data = pd.concat([data, Group_cluster], axis=1)
full_data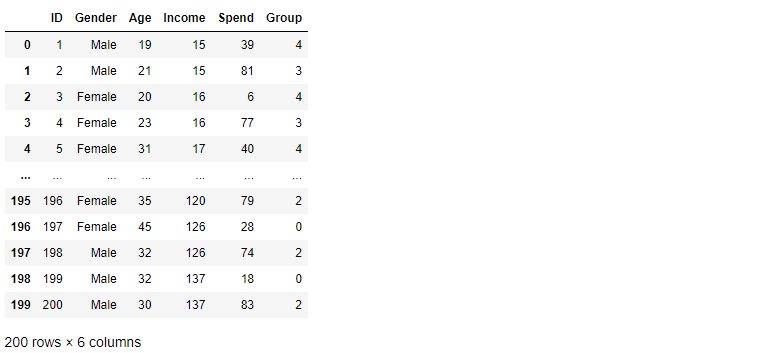
k_means의 결과를 원래 data셋과 합치기 위해 Group_cluster에 데이터프레임 형식으로 저장하였고
변수 이름을 Group으로 명명후, concat으로 병합하였다.
그 결과 0부터 4까지 소속된 군집 번호가 만들어졌다.
kmeans_pred = KMeans(n_clusters=k, random_state=42).fit(X)
kmeans_pred.cluster_centers_군집의 특성과 해석을 위해 5개 군집의 중심좌표를 확인한다.
학습(fit)까지만 하고 결과들을 kmeans_pred에 담는다. 그 중 '.cluster_centers'가 각 좌표의 중시점 결과를 담고 있다.
kmeans_pred.predict([[100,50],[30,80]])소득과 지출이 (100,50), (30, 80)인 사람은 어떤 군집에 속할지 확인할 수 있다.
labels = [('Cluster '+str(i+1)) for i in range(k)]
labels군집 변수 이름을 'Cluster 1', 'Cluster 2', 등 이름을 다시 붙여주는 과정이다.
X=np.array(X)
plt.figure()
for i in range(k):
plt.scatter(X[y_kmeans == i, 0], X[y_kmeans == i, 1], s = 20, c = cmap(i/k), label = labels[i])
2차원 도표에 산점도를 그려보았다.
for문으로 각 개체만큼 하나씩 y_kmeans에 분석하여 저장된 좌표값을 찍는다.
label = labels[i]는 라벨마다 색을 달리하는 코드
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],
s=100, c='black', label='Centroids', marker='X')
plt.xlabel('Income')
plt.ylabel('Spend')
plt.title('Kmeans cluster plot')
plt.legend()
plt.show()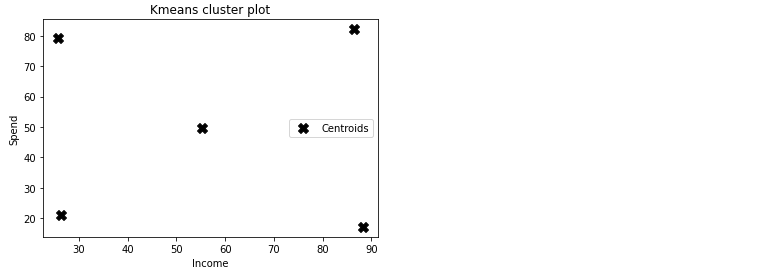
중심좌표 결과가 담긴 kmeans.cluster_centers_ 활용하여 중심점을 찍었다.
X에 첫 열의 모든 값([:, 0]), Y에 두 번째 열의 모든 값([:, 1])을 scatter 좌표로 삼고 검정색(c=black)으로 했다.
이제 절반 타이핑한건데
군집분석 나오면 그냥 틀려야지
코드가 넘 많으니까 하기 싫다~~!
'자기계발 > Python' 카테고리의 다른 글
| [혼공단 9기] 1주차 : Chapter 01 데이터 분석을 시작하며 (0) | 2023.01.08 |
|---|---|
| [빅데이터분석기사] 실기 작업형 1유형 (0) | 2022.06.26 |
| [빅데이터분석기사] 27 엘라스틱넷 (0) | 2022.06.25 |
| [빅데이터분석기사] 26 라쏘회귀모델 (0) | 2022.06.25 |
| [빅데이터분석기사] 25 릿지회귀모델 (0) | 2022.06.24 |