
한빛미디어에서 진행하는 혼공단 9기 1주차!
나는 이전에 데이터분석, Python에 관심이 있어서 빅데이터분석기사 자격증 준비를 했었다.
하지만 성실하지 않은 성격 탓에 벼락치기로 시험 준비를 하게 되더라...
자격증 취득은 어찌 성공했지만 자기계발이라는 순수한 본 목적 달성은 실패해버렸다.
내 스스로 공부하면 좀 더 공부다운 공부를 할 수 있지 않을까 싶어
혼공단 9기를 신청했고, 커리큘럼 따라 <혼자 공부하는 데이터분석> 교재로 독학한다.

신청 전 교재 목차를 보니 API도 활용 내용도 있고, Python의 다양한 패키지도 다뤄볼 수 있을 것 같았다.
이 책이 이번에 따끈따끈하게 새로 나온 신상 IT 도서인 점도 마음에 들었다.
퇴근 시간 이후에 남는 시간을 활용하여 공부를 해야하는데
다른 자격증 시험도 준비해야 했기에 1주차는 진도 따라가는 것으로 만족한다.
포스팅은 내가 기억하고 싶은 것, 몰랐던 것 위주로 정리할 예정
자기계발, 독학하시는 모든 분들 파이팅👊🏻👊🏻
Chapter 01 데이터 분석을 시작하며

데이터 분석과 데이터 과학의 차이점
데이터 분석은 올바른 의사 결정을 돕기 위한 통찰을 제공하는데 초점을 맞추고,
데이터 과학은 한 걸음 더 나아가 문제 해결을 위한 최선의 솔루션을 만드는데 초점을 맞춘다.
| 특징 | 데이터 분석 | 데이터 과학 |
| 범주 | 비교적 소규모 | 대규모 |
| 목표 | 의사 결정을 돕기 위한 통찰을 제공하는 일 | 문제 해결을 위해 최선의 솔루션을 만드는 일 |
| 주요 기술 | 컴퓨터 과학, 통계학, 시각화 등 | 컴퓨터 과학, 통계학, 머신러닝, 인공지능 등 |
| 빅데이터 | 사용 | 사용 |
통계적 관점에서 보는 데이터 분석
1) 기술통계 : 관측이나 실험을 통해 수집한 데이터를 정량화하거나 요약하는 기법(평균, 최솟값, 최댓값 등)
2) 탐색적 데이터 분석 : 데이터를 시각적으로 표현하여 주요 특징을 찾고 분석하는 방법
3) 가설검정 : 주어진 데이터를 기반으로 특정 가정이 합당한지 평가하는 통계 기법
구글 코랩
파이썬 공부를 위해 지금까지 설치한 프로그램(파이참, 스파이더, 주피터 노트북 등)이 몇 개인지 모르겠다. 위 소프트웨어들은 버전도 신경써서 설치해야하고 경로 설정도 제대로 해주어야하고.. 신경써야할게 정말 많았다.
프로그램 설치를 하지 않아도 되는 구글 코랩으로 실습이 진행된다는 점 정말 마음에 든다!

구글 코랩과 일반 프로그램이 다른 점 : 일반 프로그램은 순서대로 코드가 실행되는 반면, 구글 코랩(노트북)은 셀 단위로 코드를 실행한다. 구글 코랩은 텍스트 툴 바에 있는 메뉴로 텍스트 셀 내용을 꾸밀 수 있어서 가독성 좋게 내용을 정리 하기에도 좋은 것 같다.
노트북(구글 코랩) 제한 사항
- 서버 메모리 약 12GB, 디스크 공간 100GB
- 동시에 사용할 수 있는 구글 클라우드의 가상 서버 최대 5개
- 12시간 이상 실행 불가
파일 인코딩 형식을 확인하는 코드 : chardet.detect() 함수
import chardet
with open('파일명.csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))- 파이썬의 open() 함수는 텍스트 파일이 UTF-8 형식으로 저장 되어 있다고 가정한다. 하지만 한글 텍스트는 EUC-KR 형식으로 사용하는 일이 잦다.
- mode = 'rb'는 mode 매개변수를 문자 인코딩 형식에 상관 없이 파일을 열수 있는 바이너리 읽기 모드(rb)로 지정한 것이다.
파일 인코딩 형식 지정 - 인코딩(encoding) 매개변수
with open('파일명.csv', encoding='EUC-KR') as f:
print(f.readline())
print(f.readline())- EUC-KR 인코딩 형식인 파일을 열기 위해 encoding 형식을 'EUC-KR'로 지정해주었다.
DtypeWarning: Columns (5, 6, 9) have mixed types 에러 해결
판다스는 CSV 파일을 읽을 때 효율적인 메모리 사용을 위해 조금씩 나눠서 읽는다. 이 때 자동으로 파악한 데이터 타입(예를 들어 이름 - 문자열, 나이 - 숫자)이 달라지면 경고가 발생하게 된다.
위 에러를 해결하는데 두 가지 방법이 있다.
1) 파일을 나누어 읽지 않고 한 번에 읽을 것을 명령 - low_memory 매개변수
2) 경고가 발생했던 5, 6, 9 column에 대하여 dtype 매개변수로 데이터 타입 지정해주기
#1.low_memory
df = pd.read_csv('파일명.csv', encoding="EUC-KR', low_memory=False)
#2.dtype 매개변수 지정
df = pd.read_csv('파일명.csv', encoding="EUC-KR',
dtype={'column_5' : str, 'column_6' : str, 'column_9' : str})low_memory 매개변수를 False로 지정하면 한 번에 CSV 파일을 읽어들이기 때문에 메모리를 많이 사용하게 된다. CSV 파일의 크기가 큰 경우에는 dtype 매개변수로 데이터 타입을 지정해 주는 것이 좋다.
혼공학습단(혼자 공부하는 데이터 분석 with 파이썬) 1주차_기본 미션
4. 판다스 read_csv() 함수의 매개변수 설명이 옳은 것은 무엇일까요? 3
1) header 매개변수의 기본값은 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다.
2) names 매개변수에 행 이름을 리스트로 지정할 수 있습니다.
3) encoding 매개변수에 CSV 파일의 인코딩 방식을 지정할 수 있습니다.
4) dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다.
혼공학습단(혼자 공부하는 데이터 분석 with 파이썬) 1주차_선택 미션
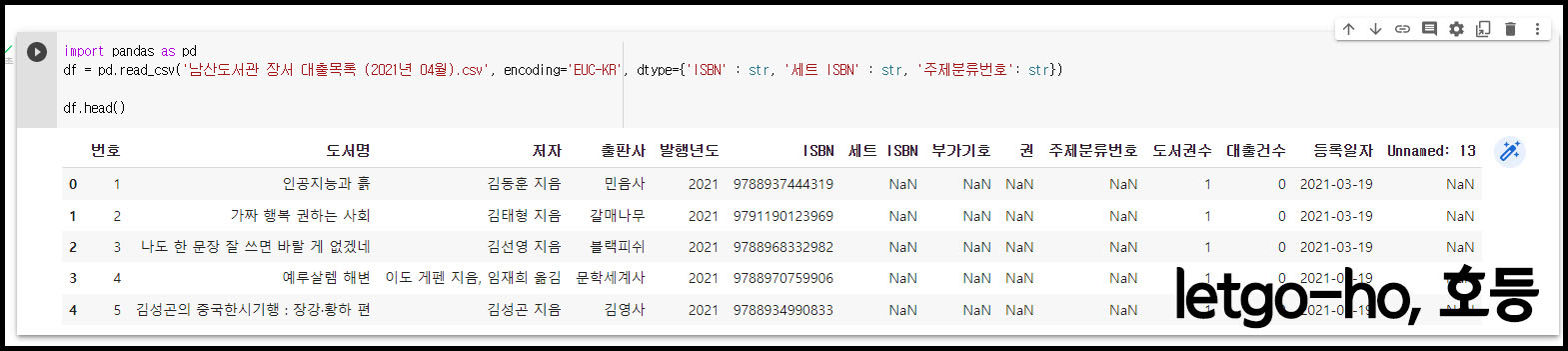
p. 71~73 남산 도서관 데이터를 코랩에서 데이터프레임으로 출력하고 화면 캡처하기
'자기계발 > Python' 카테고리의 다른 글
| [혼공단 9기] 3주차 : Chapter 03 데이터 정제하기 (4) | 2023.01.22 |
|---|---|
| [혼공단 9기] 2주차 : Chapter 02 데이터 수집하기 (2) | 2023.01.15 |
| [빅데이터분석기사] 실기 작업형 1유형 (0) | 2022.06.26 |
| [빅데이터분석기사] 28 군집분석 (0) | 2022.06.25 |
| [빅데이터분석기사] 27 엘라스틱넷 (0) | 2022.06.25 |