
인공신경망
인간의 뉴런구조와 활성화 작동원리를 근간으로 input(자극)과 ouput(반응)과의 연관을 구현한 알고리즘이다.
중간에 은닉층(hidden layers)과 노드(nodes)들을 깊고(deep) 넓게(wide) 두어 특성치로부터 분류와 회귀를 더 잘할 수 있도록 특징추출 및 분류 단계를 확장하는 역할을 할 수 있도록 한 모델이다.
입력층과 출력층 사이에 은닉층을 몇 개를 둘 건지, 은닉층에 노드를 얼마나 둘 것인지, 학습률 등 많은 파라미터가 있다.
양이 굉장히 방대하기 때문에 모두 다루지 못하고 결과 돌려보면서 간단히 실습하는데 의의를 둔다.
scikit-learn
인공신경망은 사이킷런의 neural_ntework 안에 있다.
이 중 분류 알고리즘은 MLPClassifier, 회귀 알고리즘은 MLPRegressor를 사용한다.
Par1. 분류(Classification) : MLPClassifier
1) 데이터셋 나누기, 정규화
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
X=data[data.columns[1:10]]
y=data[["Class"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
#min-max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)
위스콘신대학의 유방암 데이터로 인공신경망의 분류 문제를 실습한다.
2) 기본 모델 적용
#Part1. 분류(Classification) - MLPClassifier
from sklearn.neural_network import MLPClassifier
model = MLPClassifier()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)sklearn.neural_network로부터 MLPClassifier 라이브러리를 가져와서 model에 할당한다.
fit, predict, score 순으로 진행하여 정확도를 확인!
3) 혼동행렬과 분류예측 레포트
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)
from sklearn.metrics import classification_report
cfreport_train = classification_report(y_train, pred_train)
print("분류예측 레포트:\n", cfreport_train)
훈련데이터의 오차행렬과 분류예측 레포트를 살펴보았다.
테스트데이터셋의 오차행렬과 분류예측 레포트도 같은 방법으로 살펴본다.
4) Grid Search
#Grid Search
#hidden_layer, solver, activation 튜닝
param_grid={'hidden_layer_sizes': [10, 30, 50, 100], 'solver':['sgd', 'adam'], 'activation':['tanh','relu']}
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(MLPClassifier(), param_grid, cv=5)
grid_search.fit(X_scaled_train, y_train)
print("Best Parameter: {}".format(grid_search.best_params_))
print("Best Score: {:.4f}".format(grid_search.best_score_))
print("TestSet Score: {:.4f}".format(grid_search.score(X_scaled_test,y_test)))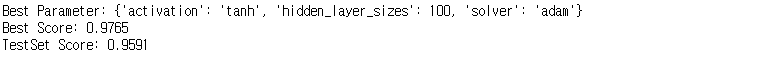
많은 하이퍼파라미터 중 hidden_layer_sizes(은닉층수), solver(옵티마이저), activation(활성화함수) 3가지를 튜닝한다.
hidden_layer_sizes는 10, 30, 50, 100으로
solver는 sgd와 adam,
activation은 tanh과 relu로 설정하여
총 16가지 조합으로 분석해보았다. (은닉층 4가지 * 옵티마이저 2가지 * 활성화함수 2가지 = 16)
탐색결과 activation은 'tanh', hidden_layer_sizes는 100, solver는 'adam' 조합으로 나왔다.
5) Random Search
#Random Search
#hidden_layer, solver와 activation 튜닝
from scipy.stats import randint
param_distribs = {'hidden_layer_sizes': randint(low=10, high=100), 'solver':['sgd', 'adam'], 'activation':['tanh', 'relu']}
from sklearn.model_selection import RandomizedSearchCV
random_search = RandomizedSearchCV(MLPClassifier(), param_distributions = param_distribs, n_iter=10, cv=5)
random_search.fit(X_scaled_train, y_train)
print("Best Parameter: {}".format(random_search.best_params_))
print("Best Score: {:.4f}".format(random_search.best_score_))
print("TestSet Score: {:.4f}".format(random_search.score(X_scale_test, y_test)))탐색결과, activation은 'relu', hidden_layer_sizes는 51개, solver는 'adam'일 때 가장 좋은 결과를 보였다.
랜덤탐색은 실행마다 결과가 다르게 나올 수 있다는 점 참고!
Part2. 회귀(Regressgion) : MLPRegressor
import pandas as pd
data2 = pd.read_csv('house_price.csv', encoding='utf=8')
X=data2[data2.columns[1:5]]
y=data2[["house_value"]]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)이번엔 주택가격 데이터로 인공신경망의 회귀 문제를 실습해보겠다.
이전 포스팅에선 주택가격 데이터로 실습하다 오류가 떴는데, 이번엔 또 오류가 안뜬다.
데이터랑 코드 둘 다 똑같은데 되었다 안되었다 하는거 보면 아주 지맘대로다
1) 기본모델 적용
#Part2. 회귀(Regression)
from sklearn.neural_network import MLPRegressor
model=MLPRegressor()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)
pred_test = model.predict(X_scaled_test)
model.score(X_scaled_test, y_test)
sklearn.neural_network로부터 MLPRegressor 라이브러리를 가져와 model에 할당한다.
정확도 확인 결과 -287%로 말도 안되는 수치가 나왔다. test 데이터 또한 비슷한 수준으로 나와버렸다.
2) RMSE 확인
#RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련 데이터 RMSE: ", np.sqrt(MSE_train))
print("테스트 데이터 RMSE: ", np.sqrt(MSE_test))
RMSE를 확인해보았더니 다른 알고리즘에 비해 매우 큰 수치가 나온 것을 확인했다.
3) 튜닝
#튜닝모델
from sklearn.neural_network import MLPRegressor
model=MLPRegressor(hidden_layer_sizes=(64,64,64), activation="relu", random_state=1, max_iter=2000)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train)이 모델은 Grid Search, Random Search의 하이퍼파라미터가 매우 다양하여 최적 조합을 찾는 것이 힘들다. 그래서 은닉층 3개, 각각 64개의 노드를 두어 조금 깊은 모델을 만들어 실습해보았다. (돌려본 것에 만족하는 정도)
은닉층, 노드 수, 활성화함수 수정 결과 정확도가 50%대까지 상승한 것이 확인된다.
4) 다시 RMSE
#RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MES_test = mean_squared_error(y_test, pred_test)
print("훈련 데이터 RMSE: ", np.sqrt(MSE_train))
print("테스트 데이터 RMSE: ", np.sqrt(MSE_test))
오차 역시 이전 결과에 비해 다소 작아진 것을 확인할 수 있다.
'자기계발 > Python' 카테고리의 다른 글
| [빅데이터분석기사] 18 의사결정나무 (0) | 2022.06.22 |
|---|---|
| [빅데이터분석기사] 17 서포트 벡터머신 (0) | 2022.06.22 |
| [빅데이터분석기사] 15 나이브 베이즈 (0) | 2022.06.21 |
| [빅데이터분석기사] 14 K-최근접이웃법(KNN) (0) | 2022.06.21 |
| [빅데이터분석기사] 13 로지스틱 회귀모델 (0) | 2022.06.20 |