
혼공단 9기 2주차!
이번 주 일이 너무 힘들고 컴활 시험일도 겹쳐서 공부를 하나도 못했다.
컴활 시험 끝나자마자 부랴부랴 벼락치기 하는데 양이 생각보다 많다!
도서관 정보나루 API 이용하려면 승인을 받아야하기 때문에 책 내용 따라하는데 약간의 제약이 있었다.
이 부분은 차주 분량 공부하면서 복습하는 차원에서 한 번 더 따라해 보아야겠다.
(다행히 뒷 부분은 제공되는 파일 덕분에 실습 잘 할 수 있었다.)
이번 챕터에서는 API의 개념과 JSON, XML 데이터 변환 기초를 공부하고, 가볍게 API 사용, 웹 스크래핑을 실습했다.

강제성이 없었으면 시험 끝났다고 대충 누워있다가 주말 다 보냈을텐데... 이렇게라도 공부하게 해주시니 감사합니다🙏
1주차에 보내주신 커피도 맛있게 잘 마셨습니다. 감사합니다!
이번 주 일주일치 내용을 하루 안에 공부하느라 하루 종일 붙잡고 있었고 너무 힘들었다. 담주엔 절대 밀리지 말아야지... 절대
chapter 02 데이터 수집하기

용어 정리
◾ API : 두 프로그램이 서로 대화하기 위한 방법을 정의한 것
◾ 웹 기반 API : HTTP 프로토콜을 사용하며 일반적으로 CSV, JSON, XML 등과 같은 파일을 사용
(CSV는 복잡한 데이터 구조를 표현하기 어렵고, 각 행마다 항목 개수가 정확하게 맞지 않으면 읽기 어렵기 때문에 웹 기반 API에선 JSON이나 XML을 더 많이 사용한다.
◾ JSON(JavaScript Object Notation)
파이썬의 딕셔너리와 리스트를 중첩해 놓은 것과 비슷한 모습(키와 값을 콜론으로 연결한 형태)
웹 기반 API로 데이터를 전달할 때는 파이썬 딕셔너리가 아니라 텍스트로 전달해야한다. (웹 기반 API가 사용하는 HTTP 프로토콜이 텍스트 기반이기 때문이다.)
◾ XML(eXtensible Markup Language)
컴퓨터와 사람이 모두 읽고 쓰기 편한 문서 포맷을 위해 고안되었으며 엘리먼트들이 계층 구조를 이루면서 정보를 표현한다. 구조적이지 못하기 때문에 API에서는 적절하지 않지만 웹 페이지를 표현하는 데 뛰어나다.
◾ HTTP GET 방식
파라미터와 값은 '='로 연결하고, 파라미터 사이는 '&'로 연결, 호출 URL과 파라미터는 '?'로 연결하는 방식
(광고 링크에 UTM 붙일 때 '?', '&' 기호 사용했었는데 이런걸 HTTP GET 방식이라고 부른다는거 첨 알았음)
파이썬 객체를 JSON 문자열로 변환 : json.dumps()함수
import json
d = {"name" : "혼자 공부하는 데이터 분석"} #Python 딕셔너리
d_str = json.dumps(d, ensure_ascii=False) #문자열(str)로 변환
print(d_str) #결과 > {"name": "혼자 공부하는 데이터 분석"}파이썬 객체를 JSON 문자열로 변환할 땐 json 패키지 안에 있는 json.dumps() 함수를 사용한다.
ensure_ascii 매개변수를 False로 지정한 이유는 위 함수가 아스키문자 외 다른 문자들은 16진수로 출력하기 때문이다!

위 캡처본은 ensure_ascii 매개변수 값을 True로 했을 때 결과이다.
한글이 16진수로 변환된 것을 확인할 수 있다.
JSON 문자열을 파이썬 객체로 변환 : json.loads() 함수
d2 = json.loads(d_str)
print(d2['name']) #결과 > 혼자 공부하는 데이터 분석
좀 더 복잡한 JSON 배열 만들기
d4_str = """
[
{"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022},
{"name": "혼자 공부하는 머신러닝+딥러닝", "author": "박해선", "year": 2020}
]
"""
d4 = json.loads(d4_str)
print(d4[0]['name']) #결과 > 혼자 공부하는 데이터 분석◾ author 키에 ["박해선", "홍길동"] 과 같이 여러 개의 키가 들어갈 수 있다. (Python의 리스트)
◾ JSON 객체를 대괄호 안에 나열하여 JSON 배열로 나타낼 수 있다.
JSON 문자열 데이터프레임으로 변환하기(read_json()함수, DataFrame 클래스 사용)
#1) pandas 패키지 내의 read_json() 함수 사용
import pandas as pd
pd.read_json(d4_str)
#2) DataFrame 패키지 사용
pd.DataFrame(d4)
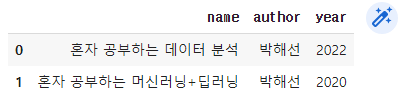
JSON을 데이터프레임으로 표현하는 두 가지 방법
1️⃣ read_json()함수와 2️⃣ DataFrame 클래스 사용
XML 문자열을 파이썬 객체로 변환 : fromstring() 함수
#XML 문자열 x_str 변수에 저장
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""
import xml.etree.ElementTree as et
book = et.fromstring(x_str)
print(type(book))xml.etree.ElementTree 모듈의 fromstring()함수로 x_str문자열을 XML로 변환했다.
json 패키지와 다른 점은 fromstring() 함수가 반환하는 객체는 단순한 파이썬 객체가 아닌 ElementTree 모듈 아래에 정의된 Element 클래스의 객체라는 것.
자식 엘리먼트 확인하기 : findtext() 메서드
#findtext() 메서드 사용
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')findtext() 메서드를 사용하면 해당하는 자식 엘리먼트를 탐색하여 자동으로 텍스트를 반환해준다.
부모 엘리먼트 아래 여러 개의 자식 엘리먼트가 있을 땐 findall() 메서드와 for문을 사용하여 쉽게 출력할 수 있는데 이 내용은 교재 100p 내용 참고하기!
데이터프레임 행과 열 선택하기 : 직접 지정, loc 메서드, iloc 메서드
import gdown
gdown.download('http://bit.ly/3q9SZix', '20s_best_book.json', quiet=False)
import pandas as pd
books_df = pd.read_json('20s_best_book.json')
#1) 직접 지정
books = books_df [['no', 'ranking', 'bookname', 'authors', 'publisher', 'publication_year', 'isbn13']]
books.head()
#2) loc 메서드
books_df.loc[[0,1],['bookname','authors']]
#3) iloc 메서드
books_df.iloc[[0,1],[2,3]]원하는 데이터만 쉽게 보기 위해 원하는 행만 열을 가져와야한다.
직접 지정하는 방법도 있겠지만, loc 메서드와 iloc 메서드를 사용하면 더 편하게 데이터 추출이 가능하다.
loc 메서드 안에서는 슬라이스 연산자(:) 사용이 가능하며 스텝(규칙성 있게 행 건너뛰기)도 지정할 수 있다.
(loc 메서드, iloc 메서드 차이점 이해 제대로 못함 (121p, 따로 공부하기))
HTML에서 데이터 추출하기 : 뷰티플수프
import requests
isbn = 9791190090018 #우리가 빛의 속도로 갈 수 없다면의 ISBN
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(isbn))
r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
prd_link = soup.find('a', attrs={'class':'gd_name'})
#print(prd_link)
print(prd_link['href'])위 코드는 뷰티플수프를 사용해 태그 위치를 찾는 코드이다.
find() 메서드의 첫 번째 매개변수에는 태그 이름 지정, attrs 매개변수에는 태그의 속성을 딕셔너리로 지정해준다.
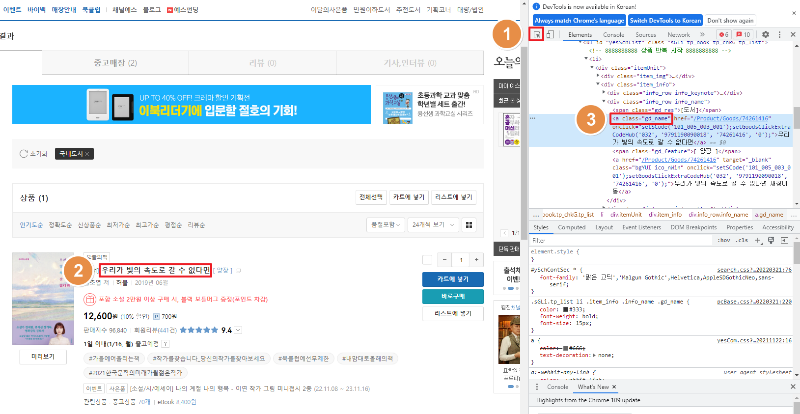
태그의 이름과 속성은 크롬 개발자 도구 창(F12키)에서 선택자를 클릭한 뒤, 내가 따고 싶은 링크 클릭하면 우측 코드창에 표기된다.
테이블 태그를 리스트로 가져오기: find_all() 메서드
#'우리가 빛의 속도로 갈 수 없다면'의 상세 페이지 가져오기
url = 'http://www.yes24.com'+prd_link['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
#print(prd_detail)
#prd_detail = soup.find('table', attrs={'class':'tb_nor tb_vertical'})
prd_tr_list = prd_detail.find_all('tr')
print(prd_tr_list)
'쪽수' 정보가 들어있는 tr태그를 찾기 위해 find_all() 메서드를 사용했다.
find_all() 메서드는 특정 HTML 태그를 모두 찾아서 리스트로 반환해준다.
find()와 find_all()의 차이
메서드 이름에서부터 알 수 있듯이 find() 메서드는 지정된 이름을 가진 첫번째 태그를, find_all() 메서드는 지정된 이름을 가진 모든 태그를 찾는다.
추가로
prd_tr_list를 출력하는데 AttributeError: 'NoneType' object has no attribute 'find_all' 이라는 오류가 났다.
하나씩 확인해보니까 prd_detail에 아무것도 있지 않다(None)으로 나왔고, prd_detail은 soup 객체의 정보를 받아야하는데내가 soup 객체를 만들지 않아서 에러가 났던 것이었음..! BeautifulSoup 클래스 객체(soup) 만드는 코드 넣어주니까 오류 해결되었다.
태그 안의 텍스트 가져오기 : get_text() 메서드
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
break
#print(page_td)
#print(page_td.split()[0])get_text() 메서드 : 태그 안의 텍스트만 반환
위 코드는 for문으로 prd_tr_list를 순회하면서 '쪽수, 무게, 크기' 텍스트에 해당하는지 검사하고, 해당되는 텍스트를 page_td 변수에 저장하는 코드이다.
도서의 쪽수 구하는 함수 구현
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져오기
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') #HTML 파싱
# 검색 결과에서 해당 도서 선택
prd_info = soup.find('a', attrs={'class':'gd_name'})
# 도서 상세 페이지 가져오기
url = 'http://www.yes24.com'+prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# 품목정보 <div>를 선택
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
# 테이블에 있는 <tr> 태그 가져오기
prd_tr_list = prd_detail.find_all('tr')
# 쪽수가 들어 있는 <th>를 찾아 <td>에 담긴 값 반환
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''앞에서 실습 했던 모든 과정을 하나의 함수로 만든 코드이다.
판다스 데이터프레임은 한 행씩 순차적으로 처리하는데 최적화되어 있지 않기 때문에 for 문으로 반복하는 것은 비효율적인 방법이다. 그렇지만 각 행 혹은 각 열에 원하는 함수를 적용해 주는 여러 가지 방법을 제공한다고 한다. 원하는 함수를 적용해 주는 방법을 제공한다는게 어떤 느낌인지 감이 잘 오지 않는다.
데이터프레임과 시리즈 합치기
top10_books = books.head(10)
def get_page_cnt2(row):
isbn = row['isbn13']
return get_page_cnt(isbn)
page_count = top10_books.apply(get_page_cnt2, axis=1)
page_count.name = 'page_count' #열 이름으로 사용될 이름 지정
top10_with_page_count = pd.merge(top10_books, page_count, left_index=True, right_index=True)
top10_with_page_count데이터프레임 행 혹은 열에 함수를 적용해수는 apply() 메서드
위에서 말한 '함수를 적용해 주는 방법을 제공한다'는게 이런건가보다.
apply() 메서드 첫 번째 매개변수는 실행할 함수를 넣어주고 axis에는 1(행에 적용, 0은 열에 적용)을 넣어준다.
get_page_cnt2() 함수의 결괏값은 page_count 변수에 판다스 시리즈 객체로 저장된다.
merge() 함수의 첫 번째, 두 번째 매개변수엔 합칠 데이터프레임 혹은 시리즈를 넣고, 인덱스 기준으로 합칠 경우엔 left_index와 right_index 매개변수 값을 지정해주어야 한다.
혼공학습단(혼자 공부하는 데이터 분석 with 파이썬) 2주차_기본 미션
1. 다음과 같은 데이터프레임 df가 있을 때 loc 메서드의 결과가 다른 하나는 무엇인가요?
1) df.loc[[0, 1, 2], ['col1', 'col2']]
2) df.loc[0:2], ['co1':'col2']
3) df.loc[:2, [True, True]]
4) df.loc[::2, 'col1':'col2']
혼공학습단(혼자 공부하는 데이터 분석 with 파이썬) 2주차_선택 미션
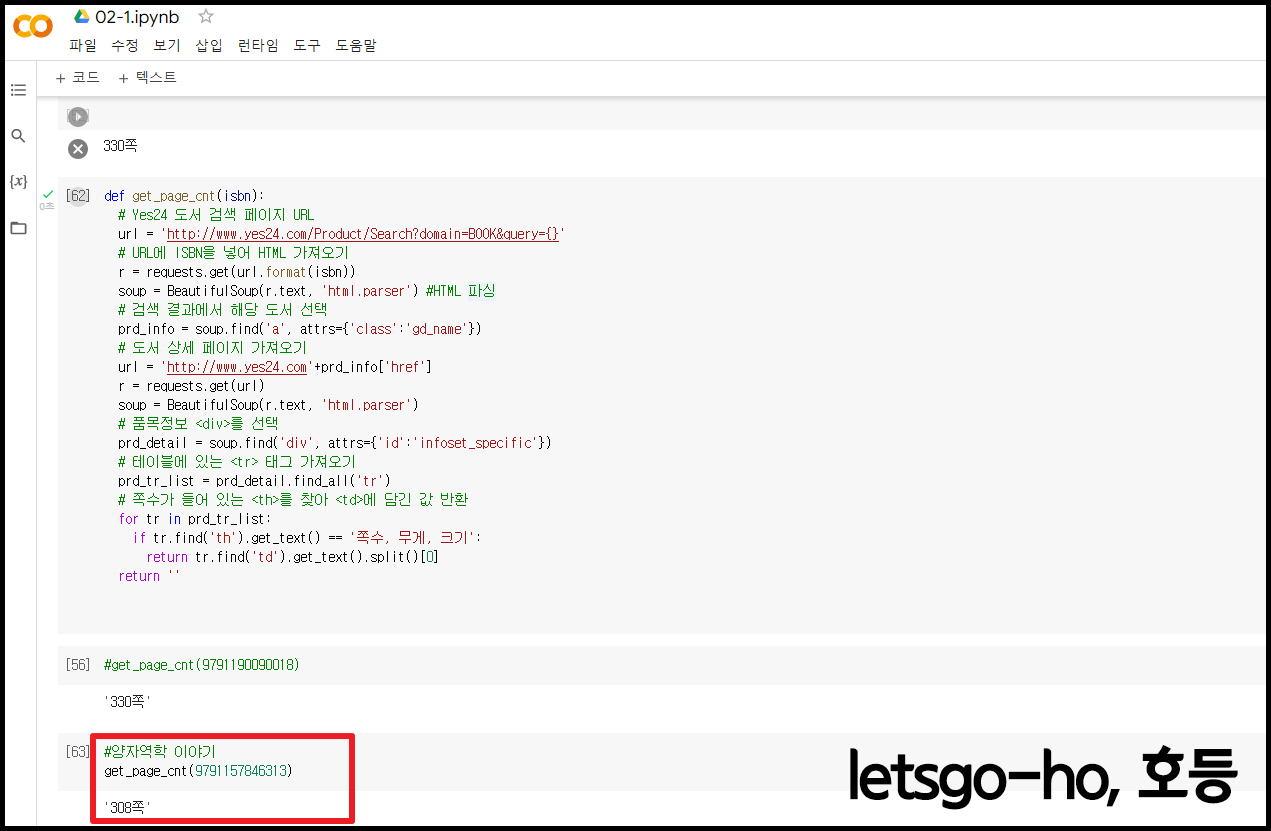
p. 137~ 138 손코딩 실습으로 원하는 도서의 페이지 수를 추출하고 화면 캡처하기
읽고 싶어서 눈여겨 보고 있는 책 [양자역학 이야기] 페이지 수를 추출해 보았습니다.
'자기계발 > Python' 카테고리의 다른 글
| [혼공단 9기] 4주차 : Chapter 04 데이터 요약하기 (0) | 2023.02.03 |
|---|---|
| [혼공단 9기] 3주차 : Chapter 03 데이터 정제하기 (4) | 2023.01.22 |
| [혼공단 9기] 1주차 : Chapter 01 데이터 분석을 시작하며 (0) | 2023.01.08 |
| [빅데이터분석기사] 실기 작업형 1유형 (0) | 2022.06.26 |
| [빅데이터분석기사] 28 군집분석 (0) | 2022.06.25 |